
2023년 10월 28일 토요일 13:00 ~ 18:00
AWS에서 주최한 컨퍼런스 "모이고 또 모이고"에 다녀왔습니다.
제가 참여한 트랙은 "트랙1 - 아키텍처/데브옵스"입니다.

0. 기조연설 - Integrating GenAI into Development Workflow
(Donnie Prakoso, Derek Bingham)
[일반적인 소프트웨어 개발 주기]
코딩 및 리뷰 -> 빌드 및 테스트 -> 배포 -> 관찰 -> 개선 (---> 코딩 및 리뷰 부터 다시 시작)
[Serverless 함수 및 컨테이너]
AWS Lambda
- 서버리스 함수
- 이벤트 중심
- 비즈니스 로직을 설계한 작은 기능
- 단기 실행 및 주문형
- 트래픽 급증
AWS Fargate
- 서버리스 컨테이너
- 유연하게 구동
- 더 큰 앱
- 장기간 실행 및 지속적으로 사용 가능
- 일관된 트래픽
[서버리스 함수를 위한 개발 도구]
AWS Lambda 작동 원리 ( 1 -> 2 -> 3)
1. Event source
- 데이터 상태 변화
- 엔드 포인트에 대한 요청
- 리소스 상태 변경
2. Function
- Node.js
- Python
- Java
- ...
3. Services
[AWS SAM vs AWS CDK]
AWS Serverless Application Modal - SAM
- SAM CLI
- 로컬에서 Lambda 개발
- YAML 정의
- 사용자 정의를 위해 CloudFormation으로 확장
- CDK로 변환
AWS Cloud Development Kit (AWS CDK)
- 인프라를 완벽하게 제어
- AWS 등을 활용하는 사전 구축된 다양한 라이브러리를 위한 허브 구축
- 기업 표준을 위한 확장 가능한 모델
- 사용 가능한 언어가 다양함
[서버리스 컨테이너를 위한 애플리케이션 개발]
AWS Fargate
Fargate는 컨테이너용 서버리스 컴퓨팅 엔진입니다.
Amazon ECS + AWS Copilot = ❤️
AWS Copilot
1. 어쩌다 AWS 인프라 구축 - 신규 서비스 개발을 위한 설계 고민들
(안정수 | 카카오)
레거시에 지쳐가던 중 신규 프로젝트 개발팀 제안을 받으셨다고 한다. 아이디어를 마음껏 실험해 볼 수 있는 환경을 회사에서 제공해주겠다고 약속받으셨고.. 국내가 아닌 "해외"타겟팅 서비스를 맡으셨다. 해당 서비스를 배포하면서 있었던 일들을 공유해주셨다.
그럼 어떤 일들이 있었는지 같이 알아보도록 하자
무엇을 준비해야할까?
- 네트워크 기반 구성
- 사용할 서비스 선택
- 배포환경 구성
- 모니터링
VPC를 어떻게 설계할 것인가?

IPv4 CIDR block
10.0.0.0/16은 큰 대역. 65535개의 IP가 사용 가능하다.
따라서 안정수님은 다음과 같이 VPC를 설계하셨다고 한다.
- 사내 Network 대역 연결 고려 (Direct Connect)
- 다른 팀에서 운영하는 VPC 대역과 겹치지 않게
- Develop / Production 구분하여 설계
- EKS 쓴다면 X2 배 대역
결론 : 너무 크지 않게 & 겹치지 않게 !!!
Subnet 구성을 어떻게 할 것인가?
Private subnet을 중심으로 역할에 따라서 구분하여 구성
- Nat
- EKS Worker
- Database
- VPC Endpoint
총 4개의 서브넷으로 구성 !!!
AZ는 몇 개로 해야할까?
- AZ를 많이 사용하면 비용 증가
- VPC 대역도 고려
- Aurora 다중 AZ를 필요로 한다면 3 AZ
- 2 or 3 AZ
실제로는 2개의 AZ 사용 !!!
어떤 AWS 서비스를 선택할 것인가?
AWS에는 서비스가 무수히 많기 때문에 필요한 서비스를 고르는 것도 고민이 필요하다
필요한 서비스
- Computing - EKS
- Database - RDS for MySQL
- Storage - S3 / CloudFront
- Cache - Redis on ElasticCache
- Push Integration - SNS, SQS, Kinesis
Computing - EKS
- 사내 Private Cloud에서 K8S 경험 있음
- AWS Managed 라서 더 편리하기를 기대
- 실제로는 가장 많은 시간이 소요됨
다시 한다면 선택하지 않을 것 !!!
EKS 노드 그룹 선택하기
- Managed : 인스턴스 타입, 사이즈만 정하면 됨
- AWS Fargate : pod에 정의된 리소스에 맞게 1 pod / 1 instance 알아서 맞춰줌
- Self-managed : 이걸 쓰면 직접 kubelet, kube-proxy 고려해야함
EKS 노드 그룹 선택하기 - fargate
- Fargate는 vCPU, Memory 조합이 정해져 있어, CPU가 많이 필요하거나 메모리가 많이 필요한 애플리케이션은 적합하지 않음
- Node를 관리하지 않아 좋지만, Node를 관리해야하는 필요가 있기도 함 (DaemonSet이 필요한 경우가 종종 있음)
- Public Subnet 사용 불가, NLB 사용 불가
Fargate를 사용하기 어려운 경우도 있음을 알고 있어야함
EKS 노드 사이즈 선택하기
- EKS Pod는 IP 할당시 VPC 대역의 IP를 할당 받음 = Pod가 많으면 VPC 대역에 남는 IP 자원이 줄어듬
- 하나의 Worker Node가 여러개의 IP를 점유할 수 있음
- Node(인스턴스) 사이즈에 따라 연결할 수 있는 ENI 개수 차이있음
- Node(인스턴스) 사이즈에 따라 가용 네트워크 대역폭의 차이 있음
따라서 너무 작지 않게 선택하자
EKS OIDC 연결
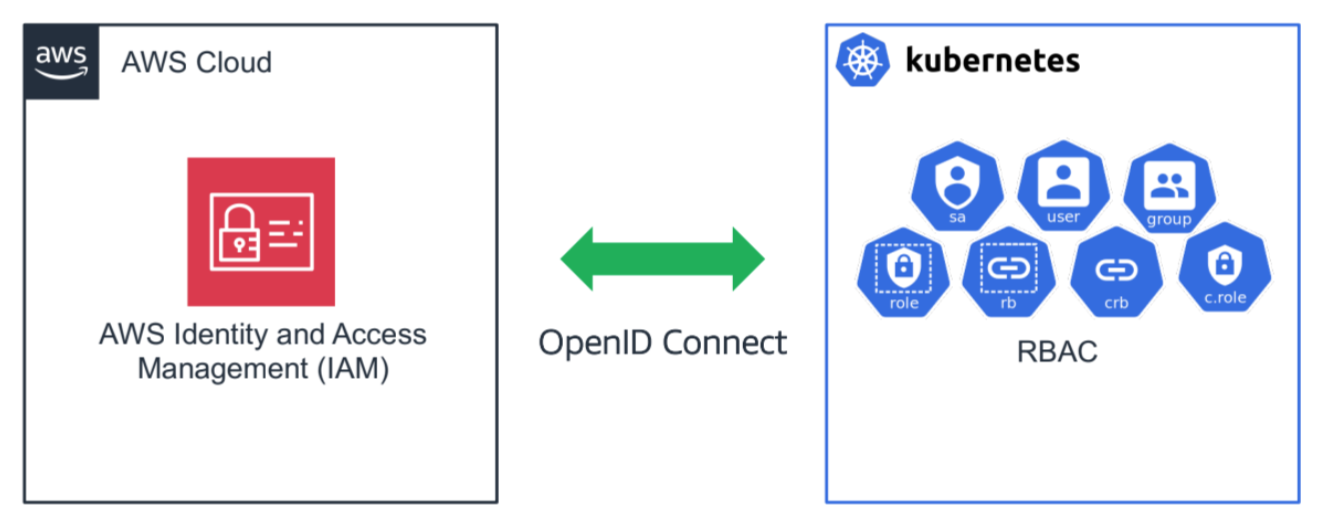
가장 많은 시간 소요
Database - RDS
- Aurora 가 좋지만 사내 DB 조직 지원
- 많은 처리량이 필요하지 않음
- 따라서 가장 익숙한 Database MySQL 사용
Storage - S3(with Cloudfront/Endpoint)

- 콘텐츠 스토리지로 S3 사용
- IA 기능 활성화
- Cloudfront로 CDN 처리
- Private Subnet에서 VPC Endpoint로 연결
Push Integration - SNS, SQS, Kinesis

- Push Integration을 위해 사용
- 두 개의 프로덕트에 각각 SNS / Kinesis 사용
- 기존에 Kafka를 익숙하게 사용하여 Kinesis 시도
결론 : Kinesis는 Too much
어떻게 배포할 것인가?
- 배포 방법으로 선택할 수 있는 다양한 옵션들
- 자체 Container Build 시스템 존재
- 보안 스캔은 사내에서 진행해야함
배포 파이프라인

ECR로 Mirroring
Monitoring - CloudWatch, OpenSearch
- Cloudwatch를 기반으로
- 일부 Log는 OpenSearch로 확인
- Application Performance Management는 사내 시스템 사용
ETC - Lambda, Elasticache
- Image Thumbnail 생성에 Lambda 활용
- Redis Cache 용도로 ElastiCache 활용
Infrastructure as Code - Terraform
- 테라폼을 사용하면서 각 서비스의 옵션 파악
- 기본값은 기본값일 뿐
- Production에 필요한 설정값을 잘 파악해야함
- RTFM - 매뉴얼을 꼼꼼하게 확인하자
프로젝트를 통해서 알게된 점
- AWS 서비스는 너무나 다양하다. 아는만큼 활용할 수 있다
- 한번에 infrastructure를 완벽하게 구성하려고 하지 말고 여러 번 바꿀 수 있다는 것을 고려하자
- IaC를 통해서 언제든지 새롭게 만들어보고 테스트하기
- Default는 Default일뿐, Production 옵션 확인 필수
- 잘 모르는 부분 넘어가지 말고, RTFM
프로젝트 런칭 결과는?
성공적으로 시장에 런칭!
하지만 결과는 아무도 알지 못했다...
2. 카오스 엔지니어링과 AWS Fault Injection Simulator
(윤종원 | AUSG)
상당히 나이가 어려보이시는 발표자분이 나오셨는데 경험이 많아보이셨다. 우리가 잘 알고 있는 Netflix를 예시로 설명해주셨는데 꽤나 재밌게 들었다. 같이 한번 알아보자.
오늘의 목표
- 카오스 엔지니어링이 우리에게 주는 것
- 카오스 엔지니어링을 잘 하는법
- 카오스 엔지니어링을 쉽게 하는 법
카오스 엔지니어링?

- 카오스 엔지니어링을 들어보신 분?
- 당신은 들어보셨나요?
- 카오스 엔지니어링을 해본 적이 있으신 분?
- 들어보셨다면 당신은 해보셨나요?
Netflix
- 맞다 우리가 아는 그 넷플릭스 맞다... 두둥
- 1997년 우편을 통한 DVD 배달 서비스로 시작
- 2007년부터 'OTT 스트리밍 서비스' 시작
- 2008년 데이터베이스 장애로 인해 3일 동안 DVD를 배송하지 못하는 일이 발생!
- 데이터센터의 RDB와 같은 SPOF(단일 장애 지점)으로부터 벗어나 클라우드 위에 안정적이고, 확장 가능한 분산 시스템으로 넘어가기로 결심!
- Chaos Monkey
- 프로덕션 환경에서 실행되는 인스턴스 혹은 컨테이너를 무작위로 종료
- 엔지니어가 장애에 더 자주 노출되도록 하여 복원력이 뛰어난 서비스를 구축하도록 동기를 부여함

Chaos Engineering
카오스 엔지니어링은 운영 환경에서도 갑작스러운 장애를 견딜 수 있는 시스템을 구축하기 위해 시스템을 실험하는 분야입니다
다음에 대해 얼마나 확신하시나요?
- 무작위로 한 개의 서버가 꺼진다면?
- 한 서비스의 네트워크 지연이 발생한다면?
- 서버의 디스크가 꽉 찬다면?
- 레디스의 노드가 내려간다면?
- AZ 하나가 다운된다면?
- 리전 전체가 다운된다면?
카오스 엔지니어링
- 개발자와 SRE 팀이 협력해 카오스 엔지니어링을 수행
- 통제된 환경 속에서 실제 장애를 발생시키고 문제가 번지지 않는지 확인
- 학생 -> 인스턴스, 컨테이너
- 선생님 -> 개발자 / AWS
- 소방 훈련을 계획한 소방관 -> 카오스 엔지니어링을 계획한 SRE 팀
카오스 엔지니어링이란?
- 실제 서비스에 장애를 주입해 드러나지 않았던 아키텍처 상의 문제를 직접 드러내는 것
- 복잡한 분산 시스템에서 통제된 환경 속의 잘 계획된 실험을 통해 잠재적인 문제를 발견하는 기법
- 가설을 세우고, 실제로 그 문제를 일으켰을 때 예상한대로 동작하는지 확인하는 작업
카오스 엔지니어링 과정

왜 운영 환경에서 실험하는 것을 권장하나요?
- 시스템은 환경과 트래픽 패턴에 따라 다르게 동작
- 실제 트래픽을 샘플링하는 것이 요청을 안정적으로 캡처하는 유일한 방법
- 운영 환경에서의 온전한 신뢰를 얻기 위해서는 운영 환경에서 직접 실험해봐야 한다
꼭 운영 환경에서 실험해야 하나요?
- 운영 환경에서 실험하는 것을 권장할 뿐이지 그래야만 하는 것은 아니다
- 로컬 환경, 베타 환경, 운영 환경 등 어떤 환경에서든 통제된 환경에서, 잘 계획된 실험을 진행하면 많은 것을 배울 수 있다
- 대부분의 팀은 로컬 환경, 베타 환경에서의 무언가를 깨뜨리고 확인하는 것만으로도 시스템의 안정성을 높일 수 있다
카오스 엔지니어링이 왜 어려운가
- 매번 실험을 위해 스크립트를 작성해야 한다
- 안전하게 실험하기가 어렵다
- 현실에서 발생하는 사건을 재현하기 어려움
카오스 엔지니어링 도구
- AWS Fault Injection Simulator
- Chaos Monkey
- Chaos Toolkit
- Chaos Blade
- ...
카오스 엔지니어링을 위한 도구는 많지만 여기선 AWS에서 제공하는 도구를 소개한다
AWS FIS
- 완전 관리형 카오스 엔지니어링 툴
- 다양한 AWS 서비스들에 대한 카오스 엔지니어링 실험 수행 가능
- 호스트 수준부터 Cloud API 에러 등 사용자가 흉내내기 어려운 기능도 제공
- 중단 조건, 롤백 기능을 통해 안전하게 실험 수행 가능
- 사전에 만들어진 실험 템플릿을 통해 빠르게 실험 수행 가능
- 장애 주입 시간만큼 비용을 내는 구조 (분당 $0.10)
- 장점
- 손쉽게 장애 주입
- 직접 스크립트를 만들고, 에이전트를 설치할 필요가 없다
- AWS 관리 콘솔 / AWS CLI로 실험 수행 가능
- JSON / YAML 기반의 실험 템플릿을 통해 쉽고 빠르게 실험 시작
- 실험 템플릿 공유
- 실제 장애 사례 기반 실험
- 장애 이벤트를 순서대로 또는 병렬로 발생하도록 구성
- 시스템의 모든 수준(호스트, 인프라, 네트워크)를 대상
- 서비스 제어 수준에서 실제 장애 주입
- 안전하게 실험
- 자동 중단 조건 설정 가능
- 롤백 기능 기본 제공
- Amazon CloudWatch와의 통합
- 세분화된 IAM 제어
- 손쉽게 장애 주입
3. ArgoCD와 GitOps를 인터넷 없는 환경에서 구축하기
(정영진 | LG U+)
Agenda
- 해결하려는 문제는?
- 어떻게 해결했을까?
- 해결 과정
- 마무리
해결하려는 문제는?
기술 부채
- 유지 관리 부채
- 안정성 부채
- 기술 제품 부채
- 개발자 효율성 부채
- 보안 부채
- 의사결정 부채
해결해야 할 문제
- Problem 1. 여러 계정 구축된 EKS 관리
- 여러 계정 구축된, 인터넷이 없는 환경
- Problem 2. CLI를 통한 인프라 구축 및 배포
- Non-Immutable 인프라 구축 및 배포
- Problem 3. 히스토리 추적의 어려움
그래서 어떻게 해결하지?
- No Internet
- No Previous Infra Code
- Cannot Find History
어떻게 해결했을까?
- Solve 1. Proxy Server를 이용한 EKS 외부망 통신
- Solve 2. GitOps와 ArgoCD
- Solve 3. RBAC을 통한 ArgoCD 접근
GitOps 모델 성숙도

하지만…
- 처음부터 IaC를 하지 않았던 이유는?
- 어려워서? 시간이 없어서?
- IGW와 NAT를 못 만들게 하는게 과연 맞는 접근법일까?
- 어차피 프록시 서버를 타도록 설정하면 인터넷이 되는데...
- 배포 히스토리는 어떻게 관리하고 있는가?
- Jenkins에서 helm upgrade를 통해 관리 -> GitOps를 시도해본다면 어떨까?
4. 클라우드 트래픽과 오토스케일링 다이나믹 컨트롤
(김환수 | STCLab)
트래픽과 리소스 조절의 목표
f(x) 라는 함수가 있을 때 이 함수는 다음과 같이 정의되어 있다
f(트래픽, 리소스) =
- 시스템 장애 감소
- 고객 경험 증가
- 클라우드 비용 감소
현재 AWS의 f(x)들
- Elastic Load Balancing
- Amazon API Gateway
- Amazon DynamoDB
- Amazon EC2 Auto Scaling
- Amazon ECS
- ...
현재 AWS의 f(x)들이 Traffic Surge를 만나면?
Elastic Load Balancing, Amazon API Gateway, Amazon DyanmoDB
- 언제 scale-up or out 되는걸까?
Amazon EC2, Amazon ECS, Amazon EKS Auto Scaling
- CPU 50% 걸었더니 터지네?
- CPU 30% 걸었더니 터지네?
- CPU 10% 걸었더니 무한대로 scale-out 하네?
Traffic Surge에 대한 대책은?
고객 경험이 가장 중요하지!
- Overprovisioning, 일단 터지지 않게 늘려!
특정 이벤트 할때만 늘리자!
- 클라우드 엔지니어들 대기해!
우린 비용 절감이 먼저야!
- 어떻게든 적정 CPU Utilization 값을 찾아보자!
SLOs를 위해서 트래픽과 스케일링은 통합적, 유기적으로 관리해야함
트래픽과 스케일링 통합적 관리
Traffic & Scaling Strategies (트래픽과 스케일링 전략들)
- MSA Scaling 1
- MSA Scaling 2
- AWS Lambda
- AWS WAF
- Service Mesh
- Time-based Scaling
결론
- 인프라 구축과 운영의 목적을 세우고, 잊지 않아야 한다 -> SLOs
- 탄탄한 observability 설계 및 구축 필요
- 비즈니스의 컨텍스트, 컴포넌트 간의 컨텍스트 의존성(좌우 상하) 활용
- 최대한 트래픽 & 스케일링 자동화(automation) 구축
후기
첫 시작은 AWS 관계자분들이셨고 외국인분들이었는데 오랜만에 영어 리스닝 시간이라 당황했지만... 쉬운 영어만 써주시는 배려 덕분에 재밌게 들었다.
긴 시간동안 세션이 진행되었고 굉장히 알차게 준비가 되어있던 AWS 행사였다. 덕분에 블로그 글도 너무 길어지긴 했지만, 유익한 시간이라고 생각한다. AWS라고 하면 백엔드 개발자를 준비하는, 꿈꾸는, 이미 된 사람들은 한번쯤 거쳐가게 되는 과정이 아닐까 싶은데.
첫 두 세션은 데브옵스를 잘 모르는 입장에서도 쉽게 알아들을 수 있는 내용들이 많았고 굉장히 재밌게 들었다. 나머지 세션은 내용이 적은 것만 봐도 알 수 있듯이 상당히 실무적인 내용들이 많이 있었고 데브옵스 깊숙히 알고 있다면 더 좋을듯한 느낌의 강연이었다.
서버를 개발하는 입장에서 AWS의 여러 서비스들에 대해 알고 있다면 언제든지 활용해볼 수 있는 기회가 많아질 것이라고 생각한다. 또한, 비용적인 측면에서도 좀 더 효율적인 방법을 알 수 있지 않을까?
마지막은 AWS 준 전투식량으로 마무리합니다!

'개발이야기 > 주절주절' 카테고리의 다른 글
| [2023 LG U+ Tech Conference] 데브렐 컨퍼런스를 다녀오다 (0) | 2023.09.12 |
|---|
